1、随机+权重
RandomLoadBalance 是加权随机算法的具体实现,它的算法思想很简单。假设我们有一组服务器 servers = [A, B, C],他们对应的权重为 weights = [5, 3, 2],权重总和为10。现在把这些权重值平铺在一维坐标值上,[0, 5) 区间属于服务器 A,[5, 8) 区间属于服务器 B,[8, 10) 区间属于服务器 C。接下来通过随机数生成器生成一个范围在 [0, 10) 之间的随机数,然后计算这个随机数会落到哪个区间上。比如数字3会落到服务器 A 对应的区间上,此时返回服务器 A 即可。权重越大的机器,在坐标轴上对应的区间范围就越大,因此随机数生成器生成的数字就会有更大的概率落到此区间内。只要随机数生成器产生的随机数分布性很好,在经过多次选择后,每个服务器被选中的次数比例接近其权重比例。比如,经过一万次选择后,服务器 A 被选中的次数大约为5000次,服务器 B 被选中的次数约为3000次,服务器 C 被选中的次数约为2000次。
2、轮训+权重
RoundRobinLoadBalance 在详细分析源码前,我们先来了解一下什么是加权轮询。这里从最简单的轮询开始讲起,所谓轮询是指将请求轮流分配给每台服务器。举个例子,我们有三台服务器 A、B、C。我们将第一个请求分配给服务器 A,第二个请求分配给服务器 B,第三个请求分配给服务器 C,第四个请求再次分配给服务器 A。这个过程就叫做轮询。轮询是一种无状态负载均衡算法,实现简单,适用于每台服务器性能相近的场景下。
但现实情况下,我们并不能保证每台服务器性能均相近。如果我们将等量的请求分配给性能较差的服务器,这显然是不合理的。因此,这个时候我们需要对轮询过程进行加权,以调控每台服务器的负载。经过加权后,每台服务器能够得到的请求数比例,接近或等于他们的权重比。比如服务器 A、B、C 权重比为 5:2:1。那么在8次请求中,服务器 A 将收到其中的5次请求,服务器 B 会收到其中的2次请求,服务器 C 则收到其中的1次请求。
3、最小活跃量
LeastActiveLoadBalance 翻译过来是最小活跃数负载均衡。活跃调用数越小,表明该服务提供者效率越高,单位时间内可处理更多的请求。此时应优先将请求分配给该服务提供者。在具体实现中,每个服务提供者对应一个活跃数 active。初始情况下,所有服务提供者活跃数均为0。每收到一个请求,活跃数加1,完成请求后则将活跃数减1。在服务运行一段时间后,性能好的服务提供者处理请求的速度更快,因此活跃数下降的也越快,此时这样的服务提供者能够优先获取到新的服务请求、这就是最小活跃数负载均衡算法的基本思想。除了最小活跃数,LeastActiveLoadBalance 在实现上还引入了权重值。所以准确的来说,LeastActiveLoadBalance 是基于加权最小活跃数算法实现的。举个例子说明一下,在一个服务提供者集群中,有两个性能优异的服务提供者。某一时刻它们的活跃数相同,此时 Dubbo 会根据它们的权重去分配请求,权重越大,获取到新请求的概率就越大。如果两个服务提供者权重相同,此时随机选择一个即可。
4、一致性hash
一致性 hash 算法由麻省理工学院的 Karger 及其合作者于1997年提出的,算法提出之初是用于大规模缓存系统的负载均衡。它的工作过程是这样的,首先根据 ip 或者其他的信息为缓存节点生成一个 hash,并将这个 hash 投射到 [0, 232 - 1] 的圆环上。当有查询或写入请求时,则为缓存项的 key 生成一个 hash 值。然后查找第一个大于或等于该 hash 值的缓存节点,并到这个节点中查询或写入缓存项。如果当前节点挂了,则在下一次查询或写入缓存时,为缓存项查找另一个大于其 hash 值的缓存节点即可。大致效果如下图所示,每个缓存节点在圆环上占据一个位置。如果缓存项的 key 的 hash 值小于缓存节点 hash 值,则到该缓存节点中存储或读取缓存项。比如下面绿色点对应的缓存项将会被存储到 cache-2 节点中。由于 cache-3 挂了,原本应该存到该节点中的缓存项最终会存储到 cache-4 节点中。

下面来看看一致性 hash 在 Dubbo 中的应用。我们把上图的缓存节点替换成 Dubbo 的服务提供者,于是得到了下图:
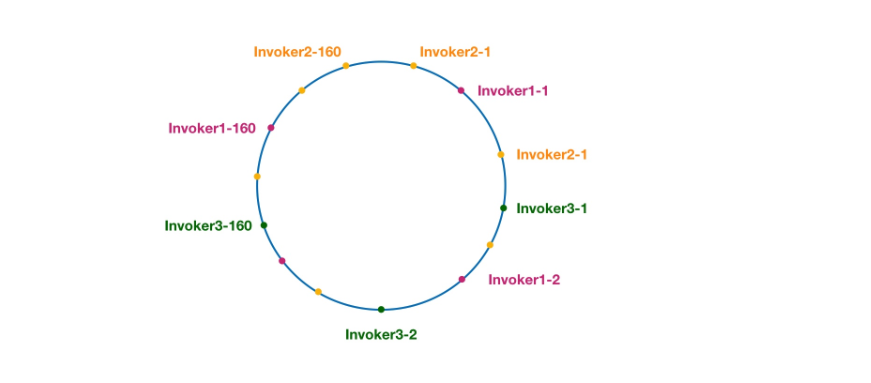
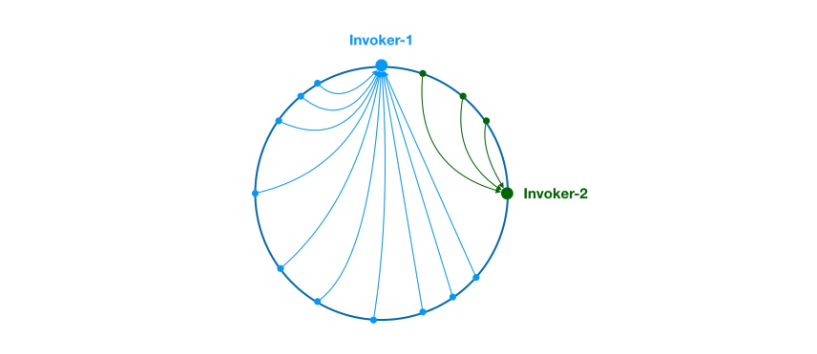
这里相同颜色的节点均属于同一个服务提供者,比如 Invoker1-1,Invoker1-2,……, Invoker1-160。这样做的目的是通过引入虚拟节点,让 Invoker 在圆环上分散开来,避免数据倾斜问题。所谓数据倾斜是指,由于节点不够分散,导致大量请求落到了同一个节点上,而其他节点只会接收到了少量请求的情况。比如:
参考连接